
Couple of days ago Nvidia released their newest badass PC Graphics card - Titan V, but this time specially geared for AI (deep learning to be precise) purposes. This post summarizes what’s in it, remove any false notions from hypes, compare against older cards wrt price point, performance and talk a bit about Google TPUs as well. Lots of people are getting to DL these days so this post should be useful for them as well. This isnt a tutorial for that, if you are interested in that, look here.
Titan V
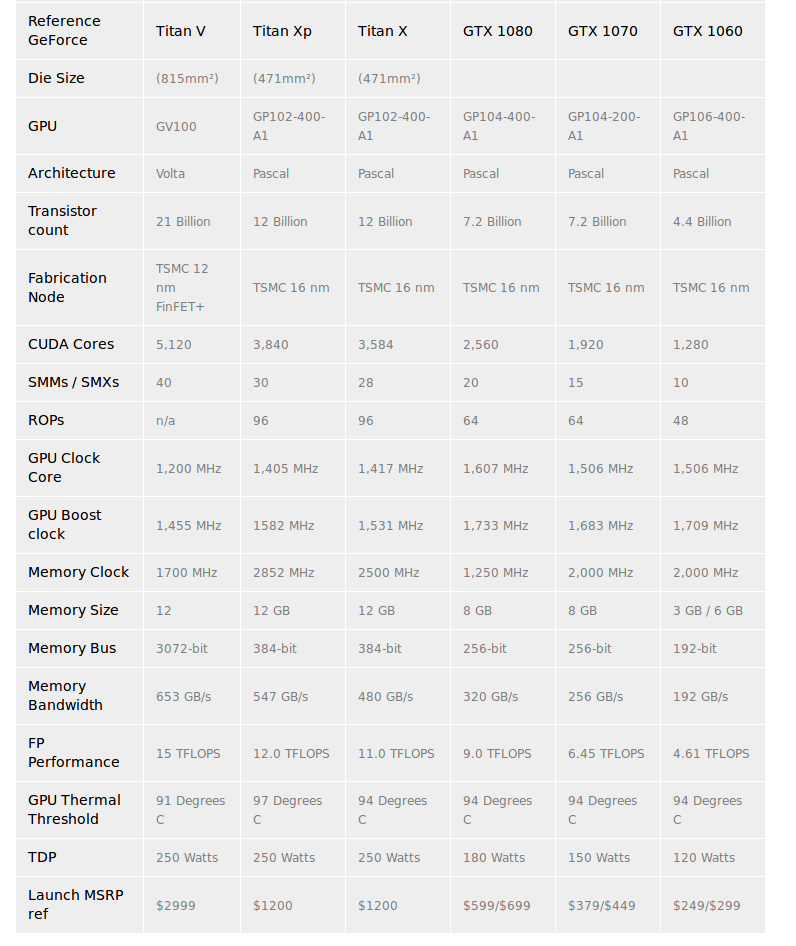
So, Titan V is a Volta architecture based card, previously released in the form of the popular server-based card V100. It follows really similar hardware specs (wrt DL). So, some of the analysis made on Titan V is applicable to V100 as well (and vice-versa). The narrative of the blog sometimes assumes that we’re interested in consumer PC cards mainly, so Titan Xp and sometimes 1080Ti (700$), I had to use P100 (15k$) to prove few points because of lack of widespread benchmarks. You can get the full info on the exact specs of Titan V by looking for “view full specs” here
What has gotten better?
- Better base architecture (Volta). This is going to be common for any other volta cards which will come.
- New
TensorCores(640) - More CUDA Cores (5120 vs 3840~ in Titan Xp before)
- HBM2! first time on a Nvidia PC card I think. (already there in P100 etc)
- 3072 bit interface ( vs 384bit GDDR5X )
- More Bandwidth - 652GB/s from 547GB/s
- HBM2 used to be a huge deal before GDDR5X as it gave 2X the bandwidth (was 350GB/s before)
- Same 250W power!!
- Mixed Precision for TensorCores (more on that below)
- (-) Clock speed is lower than Titan Xp by 100-200Mhz.
What does all the above imply? Lets see the simple stuff first, more cuda cores, better arch gives usual Nvidia new gen improvements. HBM2 gave the bandwidth a huge boost, one of the most important part for DL purposes. Going a little off topic briefly below (sorry).
Memory Bandwidth
You calculate Memory Bandwidth using 3 parameters.
- Memory Clock (Memory Speed) (MHz)
- Memory Interface (Memory Bus) (bits)
- MB = MC * MI
So GDDR5 (1080 and previous) has low memory clock and memory interface, hence the Bandwidth was ~380GB/s. But P100 came at that time with HBM2 and just blasted Memory Interface from 300ish bit to 3000-4000 bit (V100 has 4096bit). So you instantly saw huge improvement of bandwidth in the server gfx cards. It wasnt 10x, as the Memory Clock is usually lower, it was around 3x overall. But later what happened is although interface of gddr5x is still at 384-bit, the memory clock improved to 2850Mhz so reducing the gap between HBM2 and GDDR5X, thats why the increase was less (initially didnt make sense to me, so maybe this clears up to anyone like me). But still it isnt that less, it went up 20%. Full specs is given below, to better visualize this. This is taken from guru3d.
DL part
Little bit of background info before we get into TensorCores, usually people used to train NNs on FP32 (Single Precision) but nowadays single precision also works fine for DL and has led to lot of improvements as Nvidia is exploiting it now. So, all the TeraFlops which they advertise should have a small asterix explaining the context. What they have really improved in this card is exploiting the FP16 by creating the Mixed Precision - a matrix multiplication in FP16 and accumulation in FP32 precision. To be more specific, each Tensor Core performs 64 floating point FMA mixed-precision operations per clock. So, when you compare how fast your NN will train, you’ll need to take this into consideration when sending inputs.
For example: if you continue training your models on FP32 only, then you arent going to see the 110 TFlops, you’re going to get an increase to ~15TFlops (on Titan V) from 12,11.3TFlops (Titan Xp, 1080Ti). Here you can see a table comparing P100 and V100 taken from this great blog by Dell HPC. Here, “Deep Learning” roughly translates to any method which gives best results for DL purposes. You should read their blog for detailed experiment setups and results numbers. You can also check out this blog by Xcelerit on RNNs and LSTMs benchmarking on V100s. The Dell one is for ResNet mainly. But remember this before, P100 isn’t that great, so that number doesnt translate directly to your needs. P100 is worse than 1080Ti wrt FLOPS but not wrt Memory Bandwidth, i’m yet to see DL benchmarks comparing these two. [PS: If you have access to these two (or P100 and TitanXp), please email me, I’d love to find out how 732GB/s fairs against 547GB/s with more FLOPs]

But we aren’t interested in P100 or V100. We are interested consumer GFX cards. BUUUT there’s a twist here, unfortunately on the lower level consumer level GPUs, the FP16 precision performance is very bad. This includes 1080Ti and Titan Xp. Taking the numbers from the report by Microway.
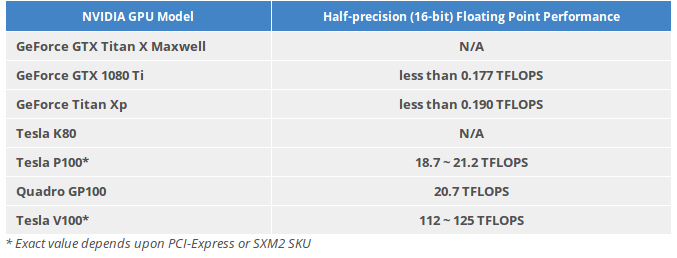
The reason of this is mainly because of the mixed precision which I told above, its not present in the 1080Tis and Titan Xps. So we just use FP32 (unlike P100). But in Volta, you’ll have to shift to FP16 (to get the best perf) so dont forget to change your code when you buy your volta cards :P
Practical Training Speedups
From the 2 reports I’ve mentioned above, we get results on practical networks like ResNet50 and LSTMs. I’m giving short numbers here, read the report for experimental setup details.
ResNet50
- In FP16: V100 (== Titan V for practical cases) is 2x better than P100
- In FP16: V100 shouldnt be compared with 1080Ti or Titan Xp
- In FP32: V100 1.5x better than P100
- In FP32: V100 would be better than Titan Xp by 1.16x (1.24x for 1080Ti)
LSTM
- Gives more speedups in more complex, bigger models. (aka more mm and accs)
- Similar as above
As you can see, it doesn’t give the 5x speedup (P100 vs V100 - 18.6 vs 112) its supposed to give theoritically. It might be that the standard networks we train still has lot of time that go into other operations. So, the theoretical bound isnt met. I’ll have to read up more on this.
Edit: Sorry! Forgot to mention that the Deep Learning libraries should be able to leverage the mixed precision training appropriately to get faster speeds. More on that on a blog post here and the paper here by Baidu and NVIDIA
Price points
- Titan V (3000$) is worth ~ 4 1080Tis (700-800$)
- Titan V worth it for single person machine without big model requirements.
- For Eg: Videos, CT Scans, MRI Scans, 3D CNNs would make me incline towards 4 1080Tis.
- Otherwise, i’m not very confident about multi-gpu training (PyTorch), have a feeling that it comes with its restrictions and might not be as fast as you’d expect.
- Multi-GPU performance will differ based on your network (RNN or CNN etc) and its size (if small enough to fit in one gpu then communication becomes bottleneck)
- and probably similar restrictions..
Fun facts
- Titan V has no SLI
- 21 billion transistors (from 12b in Xp)
Inference speedups
Dont bother about the news/fall into hype about 17x better “Deep Learning” performance bs before coming to know that its on inference. If your major time goes in training, those improvements are trivial wrt you. If not, definitely read more about it. From what i’ve seen, its because they can leverage 8-bit calculations in inference mode as you dont need that high precisions. This is what everyone are doing, be it Intel Nervana, Nvidia, TPUv1 etc.
Google TPUs
- Tensor Processing Unit TPUv1 - This was used only for inference. Apparently in production use for ~36 months. Research paper for it - 1704.04760.
- TPUv2 - This is the Training Chip. 1 TPUv2 chip has below specs. 1 unit can be seen to have 4 such chips
- 16GB HBM RAM, 600GB/s mem Bandwidtch, MXU - fp32 acc and reduced prec for multipliers
- 45 TFLOPS
- So 1 unit = 180TFLOPS, 2400GB/s BW, 64GB of vRAM
- 1 TPU Pod = 62 TPUv2 units
- 11.5 PetaFlops, 4TB of vRAM

Google designed these chips mainly for their in-house use, they aren’t planning to sell to consumers any time soon. But they would probably offer TPUv1 on Google Cloud for blazing fast inference performance.
The TPUv2 still has some amount of non-trivial modifications needed to be directly workable with normal TF or PyTorch code i think, so once they fix that, they’d start selling that too (via Cloud i guess). Right now, they are giving 1000 Cloud TPU units for FREE to researchers! :)
I recently read through a talk by Jeff Dean (Google Brain) at a NIPS17 Workshop, it has more details on this, you can checkout the slides here. The image was also taken from this slide only.
More Info, Links
- Benchmarks for DL hardware - @GraphCore should put their benchmarks here -.-
- Mixed-Precision Training of Deep Neural Networks - Nvidia Blog
- Programming Tensor Cores in CUDA 9
- Links from where I got the stats - Dell, Microway, Guru3D, Xcelerit
Future of Volta?
I’m not into speculations so haven’t looked a lot into how Nvidia will release its GPUs. It’ll be very interesting though, especially now that they can have two different audience and possible seperate focus for each. But GDDR6 is coming in 2018 and Volta will have 16Gbps memory speed, up from 11.4 of GDDR5X of TitanXp (PS: Memory clock/speed conversion between Mhz and Gbps depends on the interface)
Edit 1
Checkout this great post and it’s corresponding github repo for benchmarking popular models using different libraries. It’s in Python 3 and works directly out of the box! Great work by Yusaku Sako! Real world benchmark numbers are available in these resources :)