
Look, Listen and Learn - Relja Arandjelovi (DeepMind) and Andrew Zisserman (University of Oxford, DeepMind), published in ICCV 2017
The goal of the paper is to learn from unlabeled videos and use it for supervised video and audio tasks (individual as well as multi-modal tasks). You can get the paper from here. If you find this useful, you can cite the paper (bibtex is available at that link)
So how do they do it?
-
They make a task called Audio-Visual Correspondance (AVC).
- The task to predict a binary (whether they match or not) given an audio-video frame av pair.
- Positive set - matching av pairs.
- Negative set - non-matching randomized av pairs
-
Take 2 simple networks, one for audio and one for image frames. Take the final feature maps and combine them, pass through a couple FCs and predict binary output. They call this L^3^ net. Exact network arch. is given below. Its taken from Figure 2 of the paper.
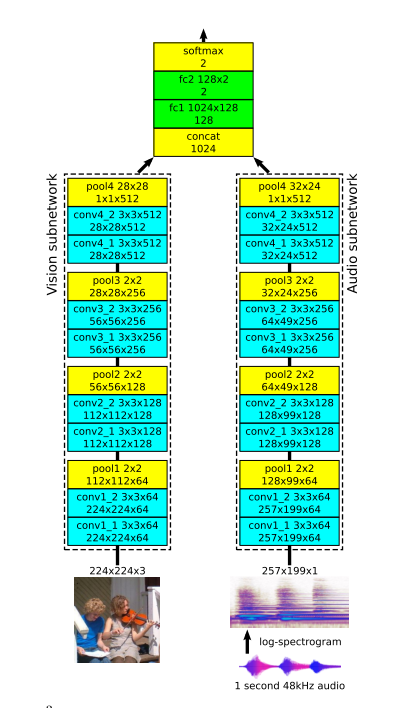
Dataset
- Flickr-SoundNet
- Random subset of 500k videos (400k train- ing, 50k validation and 50k test)
- 1st 10 secs of each video is taken.
- Kinetics-Sounds
- A labelled subset for better evaluation - 19k 10sec videos, 34 human action classes.
- Used to compare L^3^ net with supervised methods.
Implementation details
- Adam, lr 10e-4 works fine.
- Trainset 400k 10 sec vids –> Total 2 days <=> 60Million av pairs
- Positive set
- Random video -> random frame -> random 1 sec audio that overlaps with the frame. (not random 1 sec audio with middle frame)
- Negative set
- a:v :: Random video ->random 1 sec clip : Random video ->random frame
- Audio preprocessing
- Log-spectrogram computation. The 1 second audio is re- sampled to 48 kHz, and a spectrogram is computed with window length of 0.01 seconds and a half-window overlap; this produces 199 windows with 257 frequency bands
- Augmentation by increasing volume 10% random+consistent across sample
- Image preprocessing
- Uniform scaling s.t, min dim=256. Random flipLR, Brightness, saturation jittering, random cropping to 224x224
Results
- Table 1 showing results on AVC task.
- direct combination - both modalities trained seperately on action recognition, tested on AVC by taking scalar product on 34D softmax outputs
- supervised pretraining - same as above but now its trained on AVC task as well (in addition to action recognition, supervised task)
- L^3^ - same as above but no training on supervised action recognition task.
- IMO, this result doesnt prove anything as such, it just shows that for AVC task, lot of domain, supervised information is not needed.

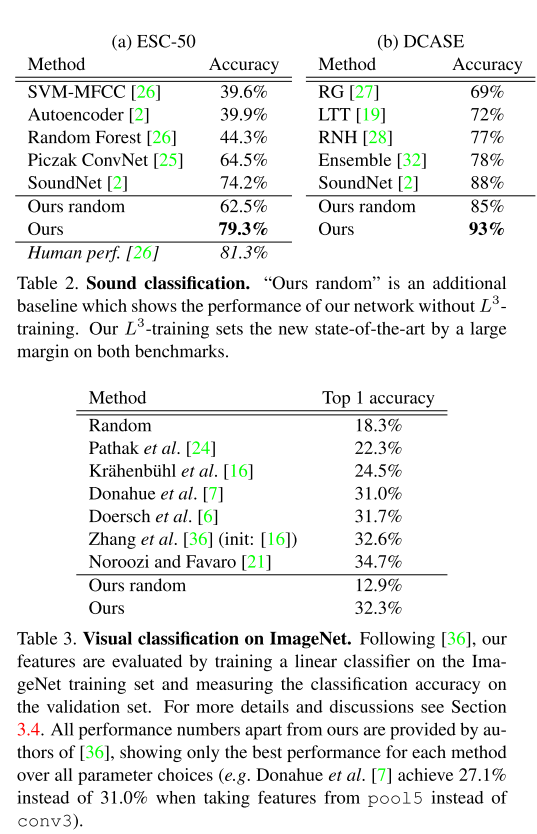
- Audio Tasks on ESC-50, DCASE
- Excellent results on both as shown in the table. Beating the SOTA on both datasets.
- Visual Tasks on ImageNet
- Results compared against other unsupervised and self-supervised methods. They show that they get comparable results but this is a very fast moving field and research topic so I wouldn’t be so sure about its validity right now. (The paper came out long ago back in May)
- More qualitative examples for each domain is given in the paper, do check it out, its cool!

Code and Reproducibility
Code wasn’t accompanied with the paper and I wasn’t able to find any other online implementations. Writing the network and the pre-processing code is trivial, I should be able to do write it in the near future. But due to lack of compute I wouldn’t be able to try and reproduce the results.
Discussion
- Simple and super cool idea. Main take-away from the paper is using this idea in different applications and use-cases.
- AVC task in itself isnt so easy because of the multimodal data which is noisy and diverse. You’d have to deal with variance in the multimodal data, like digetic and non-diegetic sound. The audio doesn’t always correspond to what happens in a video. Eg: Background music in an arena while the person is bowling.
- Despite of that, great performance on audio tasks, comparable performance on image classification task.
Related Works
- Best one is - SoundNet: Learning Sound Representations from Unlabeled Video by MIT. NIPS 2016
- They propose a training procedure wherein they take best visual recog models and train audio models using the student-teacher paradigm.
- Does transfer learning from Images to Audio domain.
- Visual categories doesn’t have meaning sometimes in audio domain so last layer is changed according to a small labeled sound data for concepts of interest.
- Uses 26TBs of video data :P
- You can get more information from the project page. They have a list of super cool papers on cross-modal learning.